입력 2012.11.03 03:02
"번역 실력 좋아진 컴퓨터·스마트폰… 빅 데이터 처리 기술 덕분"
컴퓨터가 인터넷서 스스로 학습_여러 언어로 돼있는 정부 문서들 단어·문장의 쌍 비교하며 배워…
63개 언어 번역 시스템은 하나_통계적 방법으로 동일 의미 인식 우리 팀에 언어학자 한명도 없어…
연애편지·계약서 번역은 무리_다른 언어 문서 이해할 수 있게 해 번역 수고를 줄이는 게 목적이지 사람을 대체하려는 게 아니다

서로 다른 나라 말을 하는 사람끼리 스마트폰을 이용해 자유롭게 대화한다. 한쪽에서는 영어(또는 일본어)로, 상대방은 한국어로 말하는데, 통역이 없어도 의사소통이 원활하다. 두 사람의 말을 스마트폰의 앱이 자동번역해주는 덕분이다. 여행지 등에서 쓰는 일상 언어라면 사전이 불필요하다. 인터넷도 마찬가지다. 검색 엔진 '구글(Google)'에서 외국어 자료를 찾으면, 번역 기능을 통해 검색결과를 한국어로 볼 수 있다. 과학소설(SF)에서나 보던 '기계 번역(machine translation)'이 일상화됐다.
기계 번역 서비스는 '야후!(Yahoo!)'가 시작했다. 일본 NTT와 한국 전자통신연구원(ETRI)도 최근 비슷한 서비스 앱을 내놓았다. 그러나 번역 언어수와 번역의 품질, 지원 기기 등에서 세계 1등은 구글이다. 방대한 인터넷 검색 자료를 활용해 번역 품질을 보강한 덕분이다. 기계 번역은 어떻게 이뤄지는 걸까. 기계 번역의 기반 기술을 설계하는 구글의 아쉬시 베누고팔(Venugopal) 수석 과학자를 최근 미국 캘리포니아주 마운틴뷰 본사에서 만났다.
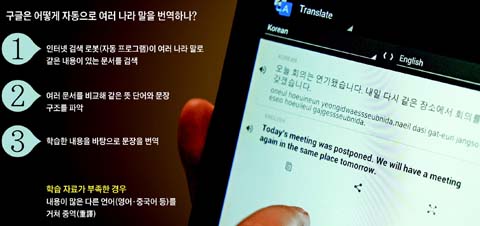
1 컴퓨터가 어떻게 번역을 하나?
"번역은 모두 인터넷 서버에서 이뤄진다. 과거에는 개별 기기에 각 언어 자료를 넣어두고 번역을 하는 프로그램도 있었다. 하지만 스마트폰·태블릿·PC 등에서 한 언어로 자료를 보내오면, 서버에서 인터넷으로 각 기기에 다른 언어로 답을 보내주는 구조다. 기계 번역은 일종의 빅데이터(일반적인 시스템으로 분석할 수 없는 많은 양의 데이터) 처리 시스템이다. 우리는 많은 데이터를 처리해 스스로 언어를 배우는 시스템을 만든다. 각 언어 학습은 시스템이 자동으로 한다. 그래서 우리 팀 대부분은 데이터 처리 기술 전문가이며, 언어학자는 1명도 없다. 언어 이해보다 데이터를 잘 이해하는 사람이 필요하다."
2 컴퓨터는 어떻게 언어를 배우나?
"모든 '학습(learning)'은 자동으로 이뤄진다. 사람이 특정 구문(構文)의 뜻을 입력하는 일은 없다. 시스템이 언어를 배우는 과정은 먼저 인터넷에 있는 여러 언어 데이터를 자동으로 읽어온다. 이를 바탕으로 스스로 언어별로 연결할 수 있는 구조와 번역문을 만든다. 컴퓨터는 서로 다른 언어로 된 문서 쌍(雙)을 바탕으로 언어를 익힌다. 국제기구나 각국 정부에는 동일한 문서가 여러 언어로 올라와 있다. 이것을 검색 엔진이 모두 읽어 각 문서를 비교하며 같은 뜻을 가진 단어·문장을 파악한다. 학습은 통계적 방법으로 이뤄진다. '안녕'과 'hello'가 함께 발견된다고 하자. 수천·수만·수십만개가 함께 발견되면 둘이 같은 뜻이란 의미가 된다. 즉, 이 시스템은 여러 언어로 쌍을 이룬 문서가 많을수록 기계가 더욱 많이 배워 더 나은 번역을 내놓는다."
3 기계 번역은 언제 시작됐나. 현재 몇 개 언어를 번역하나?
"2006년부터 기계 번역 서비스를 시작했다. 처음에는 영어·스페인어·독일어·프랑스어 등 4개 언어만 지원했다. 지금은 전 세계 63개 언어를 지원한다. 여기에는 인도의 구자라트어, 타밀어 같은 지역 언어도 포함돼 있다. 정말 중요한 건, 우리가 단 하나의 기술 시스템으로 이 언어들을 상호 번역한다는 점이다. 최초에 4개 언어를 번역하는 데 적용한 기술을 63개로 늘렸다."
4 전체 언어를 하나의 시스템으로 번역하는 이유가 있나?
"확장성 때문이다. 만약 각 언어끼리 번역하는 시스템을 따로 만든다면, 새 언어를 추가할 때마다 시스템이 새 언어를 배워야 한다. 예컨대, 영어-스페인어와 영어-프랑스어를 만들었다고 치자. 지금 시스템을 쓰면 자연스럽게 영어-스페인어-프랑스어의 상호 번역이 가능해진다. 서로를 참조해 번역 품질도 높일 수 있다. 하지만 각 언어끼리 번역하는 시스템을 구축하면 이런 경우에는 새로 만들어야 한다. 지금처럼 빠르게 63개 언어를 번역할 수 없다. 그래서 직역(直譯)하는 언어와 중역(重譯)하는 언어가 있다. 영어-한국어, 영어-스페인어는 직접 번역하지만, 한국어-스페인어는 중간에 영어를 거쳐 번역한다. 직접 번역보다 영어를 거치는 쪽에 데이터가 많아서다."
기계 번역 서비스는 '야후!(Yahoo!)'가 시작했다. 일본 NTT와 한국 전자통신연구원(ETRI)도 최근 비슷한 서비스 앱을 내놓았다. 그러나 번역 언어수와 번역의 품질, 지원 기기 등에서 세계 1등은 구글이다. 방대한 인터넷 검색 자료를 활용해 번역 품질을 보강한 덕분이다. 기계 번역은 어떻게 이뤄지는 걸까. 기계 번역의 기반 기술을 설계하는 구글의 아쉬시 베누고팔(Venugopal) 수석 과학자를 최근 미국 캘리포니아주 마운틴뷰 본사에서 만났다.
1 컴퓨터가 어떻게 번역을 하나?
"번역은 모두 인터넷 서버에서 이뤄진다. 과거에는 개별 기기에 각 언어 자료를 넣어두고 번역을 하는 프로그램도 있었다. 하지만 스마트폰·태블릿·PC 등에서 한 언어로 자료를 보내오면, 서버에서 인터넷으로 각 기기에 다른 언어로 답을 보내주는 구조다. 기계 번역은 일종의 빅데이터(일반적인 시스템으로 분석할 수 없는 많은 양의 데이터) 처리 시스템이다. 우리는 많은 데이터를 처리해 스스로 언어를 배우는 시스템을 만든다. 각 언어 학습은 시스템이 자동으로 한다. 그래서 우리 팀 대부분은 데이터 처리 기술 전문가이며, 언어학자는 1명도 없다. 언어 이해보다 데이터를 잘 이해하는 사람이 필요하다."
2 컴퓨터는 어떻게 언어를 배우나?
"모든 '학습(learning)'은 자동으로 이뤄진다. 사람이 특정 구문(構文)의 뜻을 입력하는 일은 없다. 시스템이 언어를 배우는 과정은 먼저 인터넷에 있는 여러 언어 데이터를 자동으로 읽어온다. 이를 바탕으로 스스로 언어별로 연결할 수 있는 구조와 번역문을 만든다. 컴퓨터는 서로 다른 언어로 된 문서 쌍(雙)을 바탕으로 언어를 익힌다. 국제기구나 각국 정부에는 동일한 문서가 여러 언어로 올라와 있다. 이것을 검색 엔진이 모두 읽어 각 문서를 비교하며 같은 뜻을 가진 단어·문장을 파악한다. 학습은 통계적 방법으로 이뤄진다. '안녕'과 'hello'가 함께 발견된다고 하자. 수천·수만·수십만개가 함께 발견되면 둘이 같은 뜻이란 의미가 된다. 즉, 이 시스템은 여러 언어로 쌍을 이룬 문서가 많을수록 기계가 더욱 많이 배워 더 나은 번역을 내놓는다."
3 기계 번역은 언제 시작됐나. 현재 몇 개 언어를 번역하나?
"2006년부터 기계 번역 서비스를 시작했다. 처음에는 영어·스페인어·독일어·프랑스어 등 4개 언어만 지원했다. 지금은 전 세계 63개 언어를 지원한다. 여기에는 인도의 구자라트어, 타밀어 같은 지역 언어도 포함돼 있다. 정말 중요한 건, 우리가 단 하나의 기술 시스템으로 이 언어들을 상호 번역한다는 점이다. 최초에 4개 언어를 번역하는 데 적용한 기술을 63개로 늘렸다."
4 전체 언어를 하나의 시스템으로 번역하는 이유가 있나?
"확장성 때문이다. 만약 각 언어끼리 번역하는 시스템을 따로 만든다면, 새 언어를 추가할 때마다 시스템이 새 언어를 배워야 한다. 예컨대, 영어-스페인어와 영어-프랑스어를 만들었다고 치자. 지금 시스템을 쓰면 자연스럽게 영어-스페인어-프랑스어의 상호 번역이 가능해진다. 서로를 참조해 번역 품질도 높일 수 있다. 하지만 각 언어끼리 번역하는 시스템을 구축하면 이런 경우에는 새로 만들어야 한다. 지금처럼 빠르게 63개 언어를 번역할 수 없다. 그래서 직역(直譯)하는 언어와 중역(重譯)하는 언어가 있다. 영어-한국어, 영어-스페인어는 직접 번역하지만, 한국어-스페인어는 중간에 영어를 거쳐 번역한다. 직접 번역보다 영어를 거치는 쪽에 데이터가 많아서다."
5 번역하는 언어의 구조적 차이는 번역 품질에 어떤 영향을 미치나. 영어-스페인어는 많이 비슷해도 한국어-영어는 전혀 다른데.
"이런 차이는 품질에 영향을 미친다. 프랑스어-스페인어는 비슷한 점이 많아 번역이 쉽다. 한국어-영어는 전혀 다르니까 어렵다. 더 중요한 것은 아무리 차이가 커도 시스템에 더 많은 예시가 있느냐이다. 지금 기계 번역 품질이 가장 좋은 것은 영어-중국어인데, 이는 쌍으로 존재하는 문서가 매우 많기 때문이다. 기계 번역이 언어를 배우는 방식은 사람이 공부하는 것과 흡사하다. 구조가 비슷한 언어를 공부하면 다른 언어 실력도 좋아진다. 시스템이 하나의 언어 구조를 파악하는 능력을 키우면 다른 언어에도 적용된다."
6 기계 번역의 한계는?
"현재 기계 번역의 수준은 인터넷 페이지를 보고 내용을 이해하는 데 충분하다. 하지만 이를 바탕으로 누군가에게 연애 편지를 보낸다든지, 계약서를 작성하는 것은 무리다. 인간의 언어는 굉장히 많은 표현을 담고 있는데, 우리는 아직 이를 다른 언어로 전달하는 수준에는 도달하지 못했다. 이런 것을 실현하는 것은 우리의 목표도 아니다. 기계 번역의 목표는 사람의 수고를 줄여서, 사람이 더욱 생산적인 일을 하도록 돕는 것이다. 이미 많은 미국 회사가 기계 번역을 바탕으로 중국에 문서를 보낸다. 예전에는 모두 번역사가 했으나, 이제는 기계 번역이 초벌로 문서를 만들면 번역사는 검토만 한다. 그만큼 생산성을 높일 수 있다."
7 기계 번역의 궁극적인 목표는?
"누구나 세계의 모든 정보를 찾아볼 수 있도록 하는 것이지, 인간을 대체하려는 게 아니다. 중요한 것은 다른 언어를 이해할 수 있는 수준으로 번역하는 것이며, 시적 표현을 정확히 옮겨주는 게 아니다. 우리의 목표는 세계에 있는 수많은 언어 장벽을 치워 세계가 잘 소통토록 하는 것이다. '언어가 결코 장애물이 되지 않는 세상'이 우리의 목표이다."
"이런 차이는 품질에 영향을 미친다. 프랑스어-스페인어는 비슷한 점이 많아 번역이 쉽다. 한국어-영어는 전혀 다르니까 어렵다. 더 중요한 것은 아무리 차이가 커도 시스템에 더 많은 예시가 있느냐이다. 지금 기계 번역 품질이 가장 좋은 것은 영어-중국어인데, 이는 쌍으로 존재하는 문서가 매우 많기 때문이다. 기계 번역이 언어를 배우는 방식은 사람이 공부하는 것과 흡사하다. 구조가 비슷한 언어를 공부하면 다른 언어 실력도 좋아진다. 시스템이 하나의 언어 구조를 파악하는 능력을 키우면 다른 언어에도 적용된다."
6 기계 번역의 한계는?
"현재 기계 번역의 수준은 인터넷 페이지를 보고 내용을 이해하는 데 충분하다. 하지만 이를 바탕으로 누군가에게 연애 편지를 보낸다든지, 계약서를 작성하는 것은 무리다. 인간의 언어는 굉장히 많은 표현을 담고 있는데, 우리는 아직 이를 다른 언어로 전달하는 수준에는 도달하지 못했다. 이런 것을 실현하는 것은 우리의 목표도 아니다. 기계 번역의 목표는 사람의 수고를 줄여서, 사람이 더욱 생산적인 일을 하도록 돕는 것이다. 이미 많은 미국 회사가 기계 번역을 바탕으로 중국에 문서를 보낸다. 예전에는 모두 번역사가 했으나, 이제는 기계 번역이 초벌로 문서를 만들면 번역사는 검토만 한다. 그만큼 생산성을 높일 수 있다."
7 기계 번역의 궁극적인 목표는?
"누구나 세계의 모든 정보를 찾아볼 수 있도록 하는 것이지, 인간을 대체하려는 게 아니다. 중요한 것은 다른 언어를 이해할 수 있는 수준으로 번역하는 것이며, 시적 표현을 정확히 옮겨주는 게 아니다. 우리의 목표는 세계에 있는 수많은 언어 장벽을 치워 세계가 잘 소통토록 하는 것이다. '언어가 결코 장애물이 되지 않는 세상'이 우리의 목표이다."
Copyright ⓒ WEEKLY BIZ. All Rights Reserved
위클리비즈 구독신청